Data Science and AI Projects
Relation Aware Joint Entity Relation and Extraction
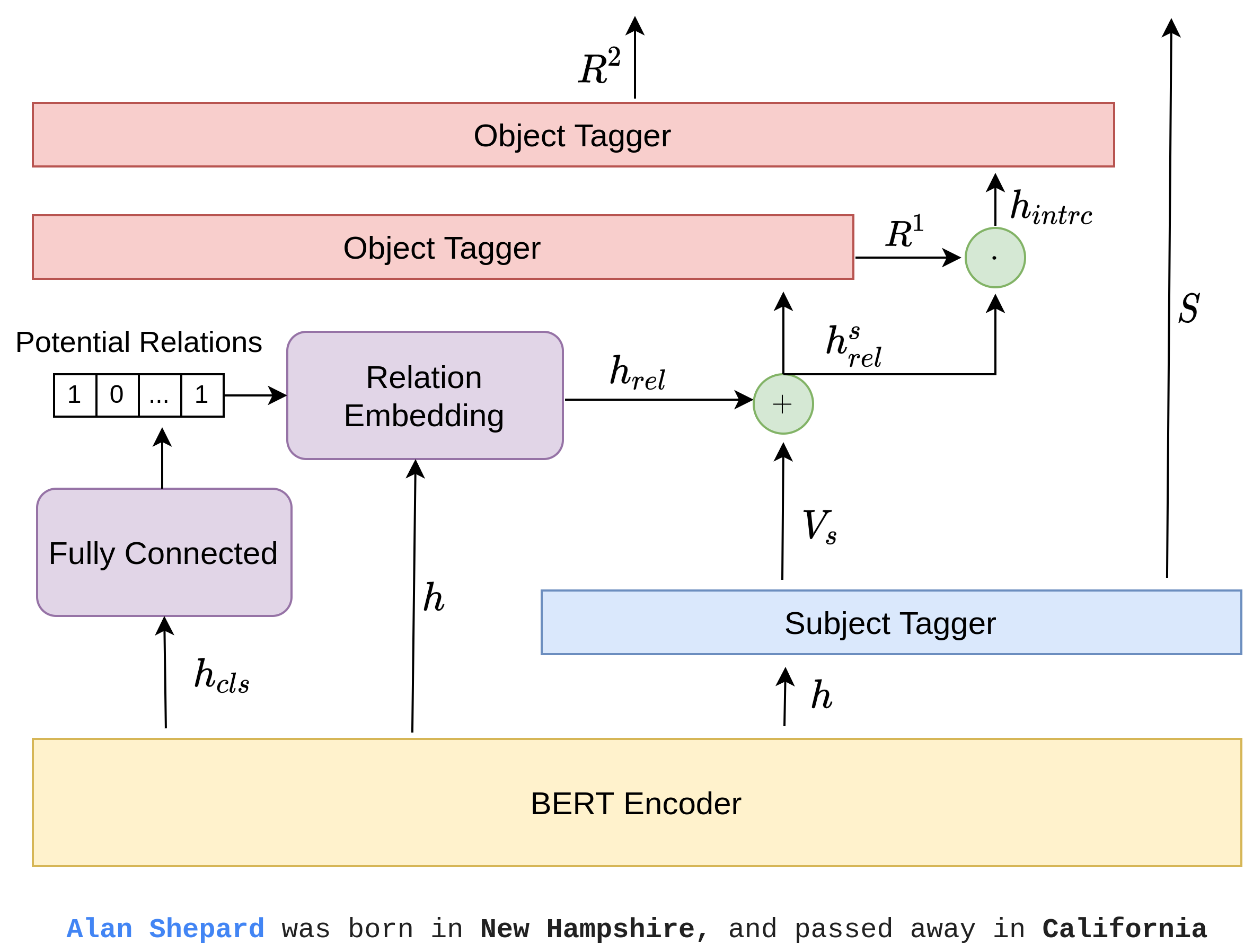
In this project, we address the challenge of joint entity and relation extraction from unstructured text, focusing on the issue of overlapping relational triples—instances where multiple relationships share common entities. Building upon the CASREL framework, we introduce a relation-aware model that incorporates both relation semantics and interactions to enhance extraction accuracy. Our approach leverages the inherent meanings of relations and their co-occurrence patterns to improve the identification of entities and their relationships. Experimental evaluations on the WebNLG dataset demonstrate that our model achieves a notable improvement, with an absolute gain of 0.96 in F1-score over the original CASREL framework. This advancement underscores the effectiveness of integrating relation-aware mechanisms in complex information extraction tasks.
Exploring Linear Regression: Closed-Form Solutions and Gradient Descent Optimization
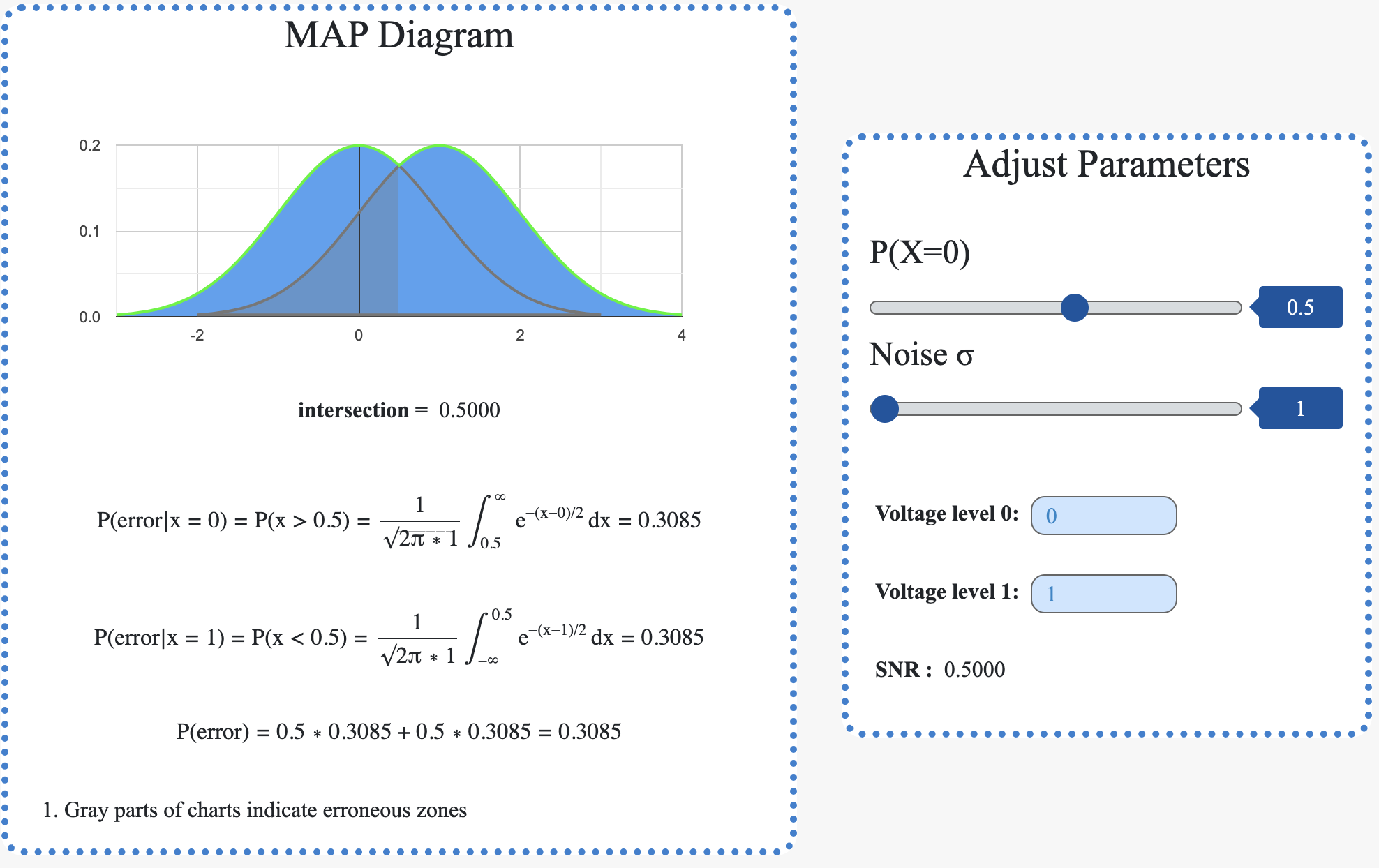
In this project, I implemented the closed-form solution to linear regression from scratch, utilizing matrix-vector representations for data handling and engaging in data visualization techniques. The project involved generating data through specific transformations, followed by performing linear regressions to predict variables in both directions. This approach provided insights into the phenomenon of "regression to the mean." Additionally, I explored the application of mini-batch gradient descent optimization for linear regression, specifically applied to the Boston housing dataset. This included normalizing features and outputs, implementing a train-validation-test framework, and experimenting with non-linear features and regularization techniques to prevent overfitting. Through this comprehensive exercise, I gained practical experience in linear regression, optimization methods, and the importance of feature engineering in predictive modeling.
Also, I investigated the application of linear and logistic regression models for binary classification tasks. By training both models on two distinct datasets, I observed that linear regression, typically used for continuous outcomes, is not well-suited for classification problems due to its assumptions and output range. In contrast, logistic regression, designed for binary outcomes, provided more accurate and reliable classifications. This comparison underscored the importance of selecting appropriate models based on the nature of the prediction task.
Data Compression and Error Correction Techniques
This project showcases my implementation of Huffman coding, convolutional coding, and the Viterbi algorithm, key techniques in data compression and error correction. Huffman coding optimizes data storage by reducing redundancy, while convolutional coding enhances the reliability of transmitted data. The Viterbi algorithm is employed for efficient error detection and correction. Through Python-based implementations, this project demonstrates my ability to apply fundamental concepts in data communication, signal processing, and algorithm optimization. It highlights my expertise in developing efficient, real-world solutions for encoding and error detection in digital systems.